The Real Problems with Chatbot Analytics in 2025

And Why Most AI Teams Still Fly Blind
Most teams believe they are measuring their AI systems.
They are not.
They are measuring proxies. Old web metrics. Infrastructure costs. Random logs. And they are hoping that somehow this gives them insight into how their AI actually behaves in production.
It does not.
In 2025, AI systems are no longer simple chatbots. They reason, retrieve documents, call tools, browse the web, and take actions on behalf of users. Yet most analytics stacks are still designed for static pages and clicks.
This mismatch creates blind spots that are expensive, dangerous, and invisible until users leave.
Let us walk through the real problems first.
Problem 1: Engagement Metrics Lie in Conversational Systems
Session duration and number of turns are misleading in AI systems.
A long conversation does not mean success. It often means the opposite.
Users repeat questions. They rephrase. They correct the model. They try again because the answer was vague or wrong. From a dashboard perspective, this looks like high engagement. From a user perspective, it is friction.
When teams optimize for longer conversations, they unintentionally reward verbosity instead of correctness.
Without understanding whether the user actually got what they needed, engagement metrics become noise.
Problem 2: Silent Abandonment Is Invisible
Most users never complain.
They do not click thumbs down. They do not write feedback. They do not explain why the answer was wrong.
They simply stop typing.
This silent abandonment is one of the most common failure modes in AI systems, and it is completely invisible to traditional analytics.
A conversation can fail catastrophically without triggering a single alert. The system did not crash. The API returned 200. The dashboard looks healthy.
Trust is lost quietly.

Problem 3: Token Costs Are Measured Too Late
Most teams only notice inefficiency when the invoice arrives.
At that point, all you know is that something was expensive. You do not know why.
Aggregate token usage does not tell you which prompts are inefficient, which intents burn the most tokens, or which conversations deliver zero value at high cost.
This creates two risks at the same time.
Financial risk from uncontrolled spend Product risk from slow, verbose responses
Without cost per conversation and cost per resolution, you cannot connect money to outcomes.
Problem 4: RAG Pipelines Are Black Boxes
Uploading documents into a vector database feels like progress.
But most teams have no idea whether those documents are actually used.
Some documents dominate retrieval. Others are never touched. Sometimes the wrong source is retrieved. Sometimes nothing relevant is retrieved at all.
Without visibility, teams assume RAG works because answers sound plausible.
Plausible does not mean correct.

Problem 5: Frustration Signals Are Hidden in Plain Sight
Frustration rarely appears as a single event.
It appears as patterns inside the conversation.
Repeated questions Escalation language All caps Requests for a human Short corrective replies
These signals live inside the text itself. They do not appear in web analytics. They do not appear in infrastructure logs.
By the time churn metrics reflect the issue, the damage is already done.
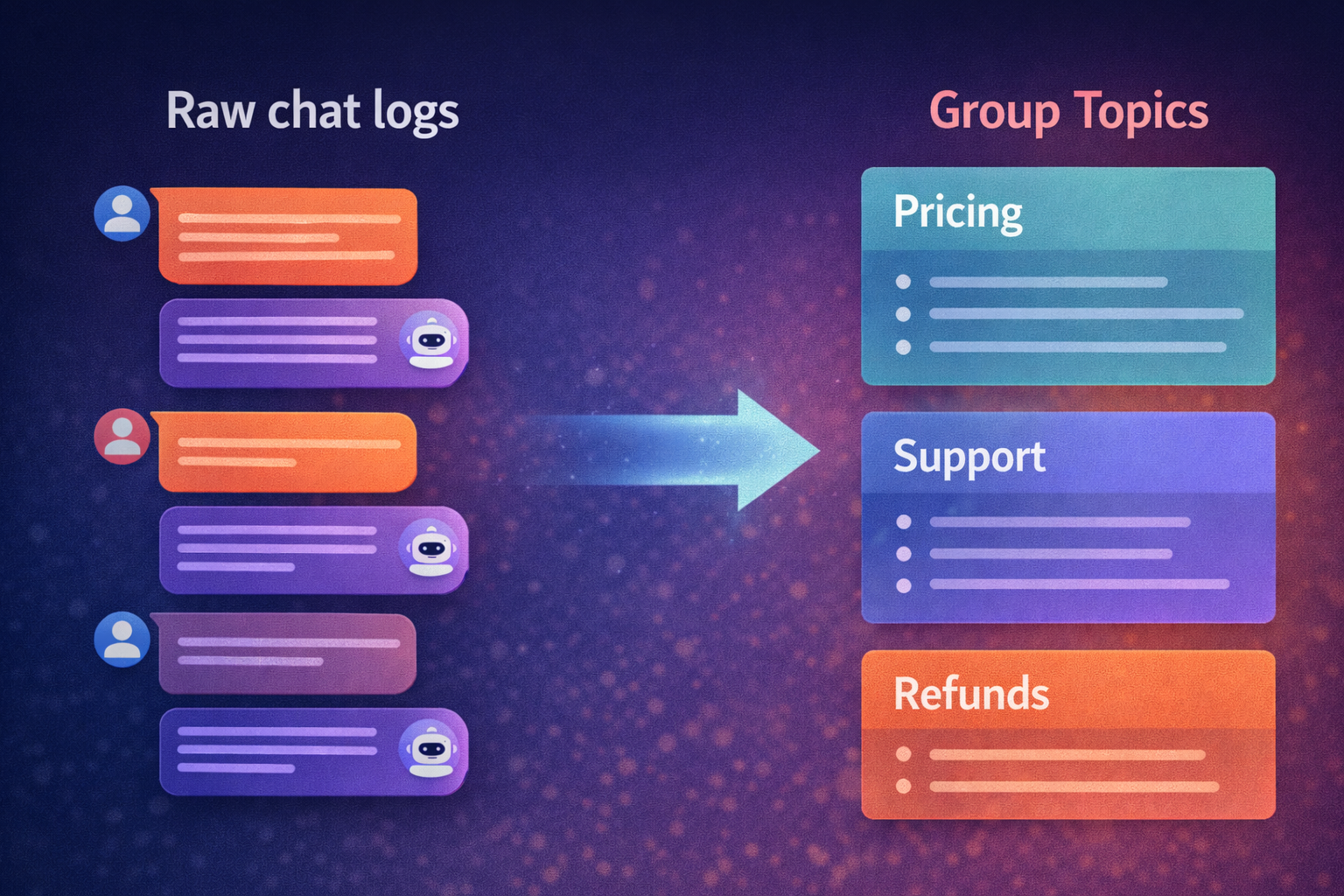
Problem 6: Logs Do Not Become Insights on Their Own
Most teams technically have access to chat logs.
That does not mean they have understanding.
Reading conversations one by one does not scale. It does not reveal demand patterns. It does not tell product teams what users actually want.
Without clustering and intent detection, conversations remain text instead of business intelligence.
[IMAGE PLACEHOLDER: Raw chat logs transforming into grouped topics like Pricing, Support, Refunds]
Why Building This Internally Rarely Works
In theory, all of this can be built in house.
Conversation ingestion Resolution detection Token attribution RAG usage tracking Sentiment analysis Intent clustering Dashboards and alerts
In practice, this becomes a parallel product. It requires constant iteration as models, prompts, and architectures evolve.
Most teams do not fail because they lack skill. They fail because analytics is not their core product.
This is exactly why Optimly exists.
Optimly: Analytics Built for AI Conversations
Optimly is designed specifically for LLM powered chatbots and agentic systems.
Not websites. Not clicks. Not page views.
Conversations.
Instead of measuring surface level engagement, Optimly focuses on what actually matters in production AI.
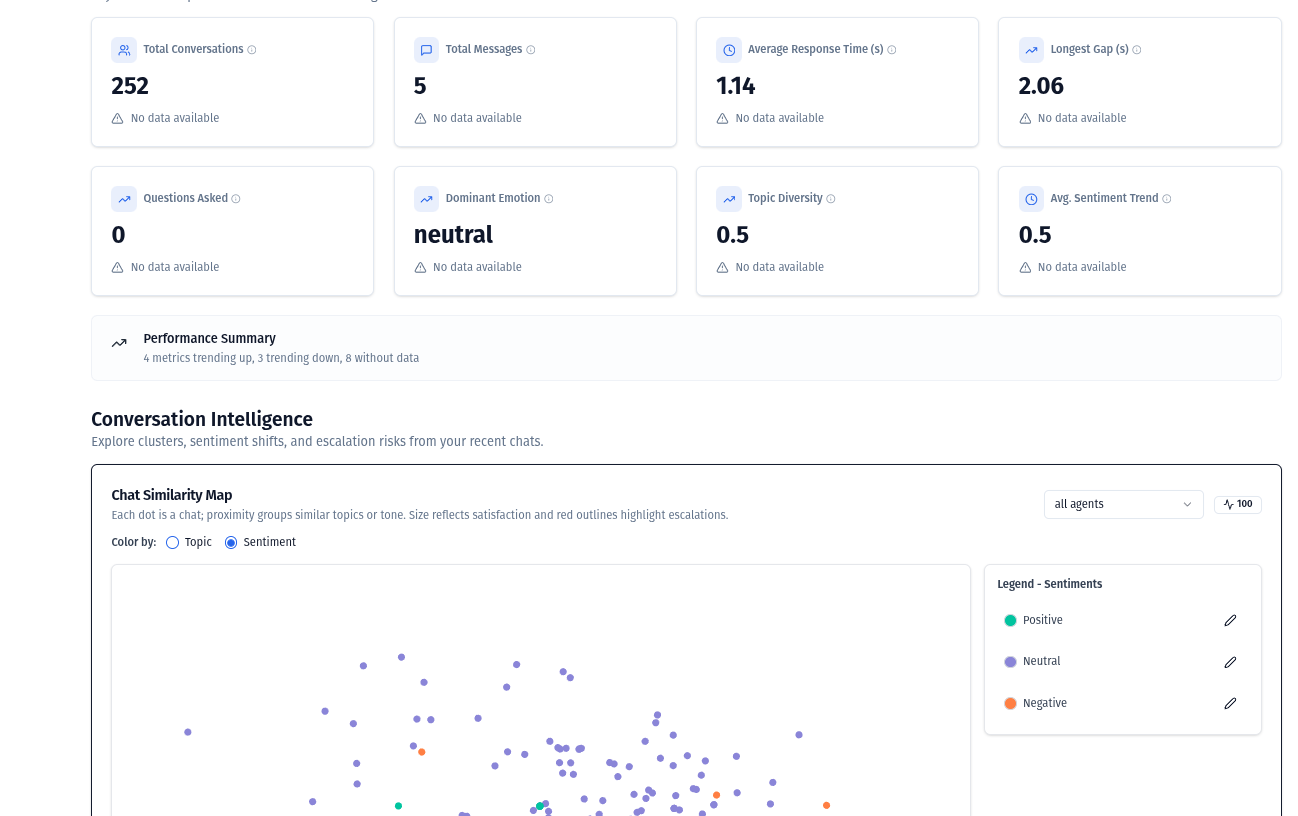
What Optimly Tracks Out of the Box
Optimly provides a full analytics layer for AI systems without requiring custom pipelines.
Resolution and abandonment detection Cost per conversation and cost per resolution Token usage broken down by prompt and session RAG usage and document retrieval analytics Frustration and sentiment signals Intent detection and topic clustering
All of this is computed automatically from your conversations and updated continuously.
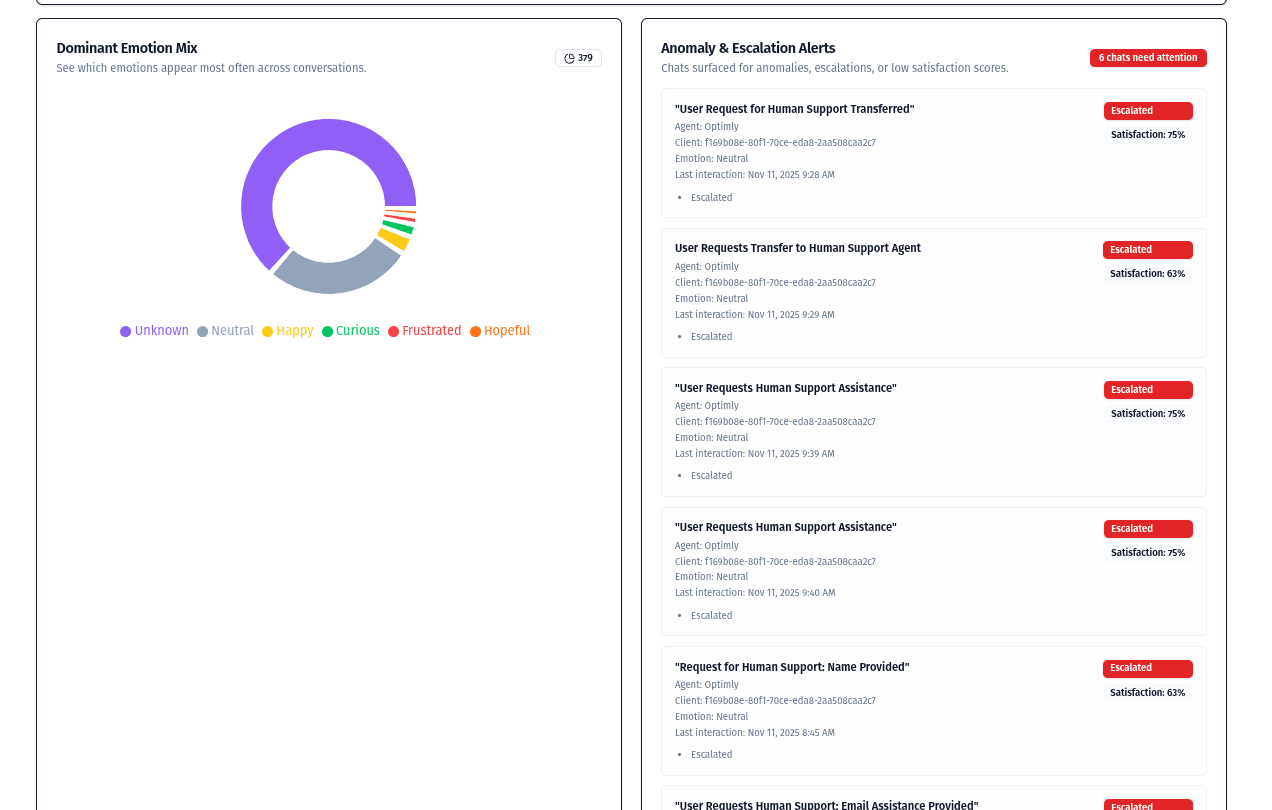
Why Teams Use Optimly
Engineering teams use Optimly to debug and optimize agents. Product teams use it to understand user demand and gaps. Founders use it to control cost and improve retention.
It turns conversations into measurable outcomes.
Creating Your First Agent with Optimly
Getting started does not require weeks of setup.
The basic flow looks like this.
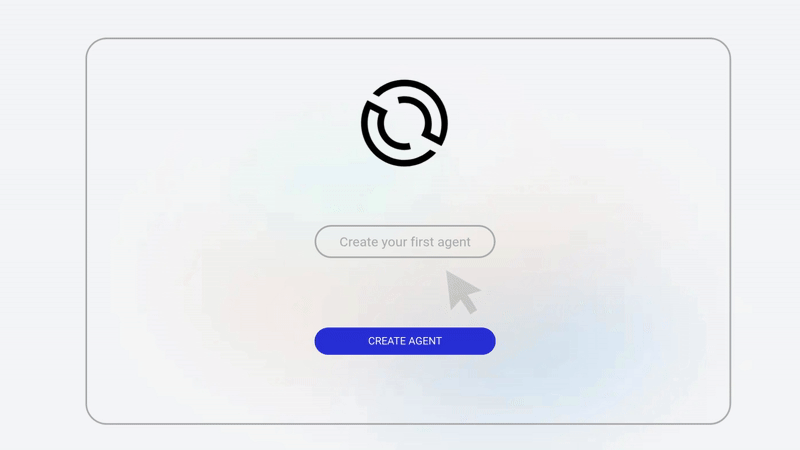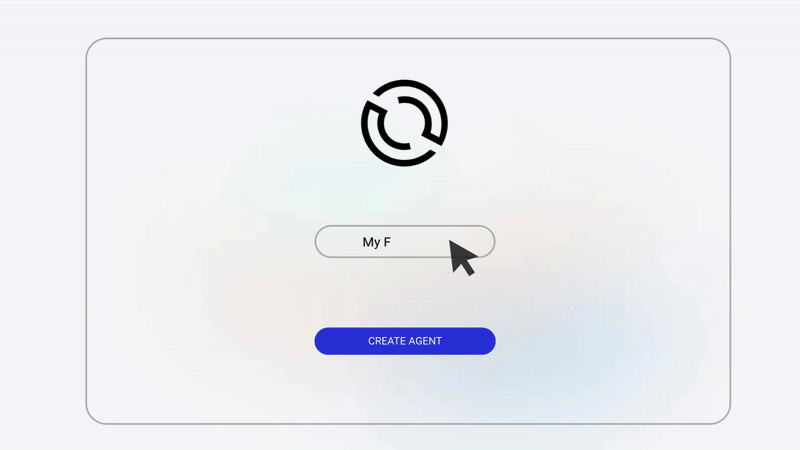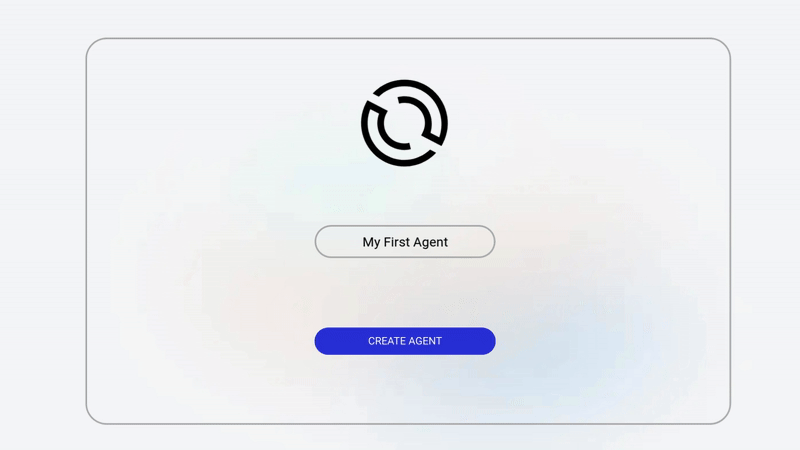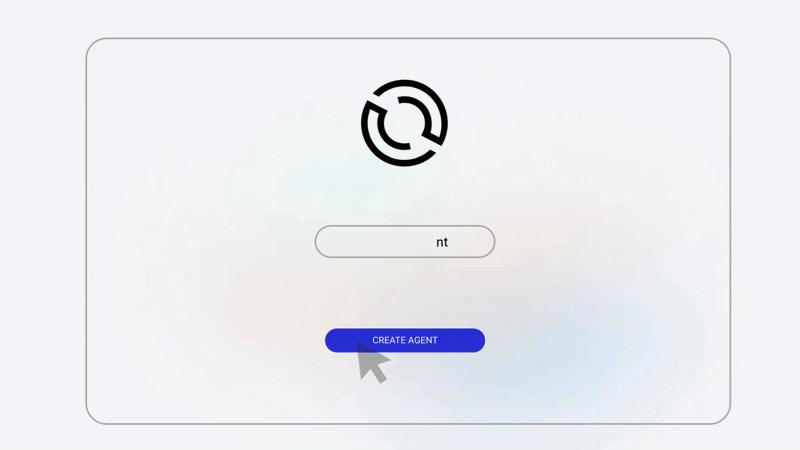
First, create an agent in the Optimly dashboard. You define the agent name, model provider, and basic configuration.
Second, integrate Optimly into your existing chatbot or agent. This is usually a single API call or SDK wrapper around your current LLM requests.
Third, start sending conversations. Optimly automatically ingests messages, responses, tokens, and metadata.
Within minutes, you can see analytics appear in the dashboard.
Resolution rates Cost per session Top intents Frustration flags Knowledge usage
No manual tagging. No custom dashboards. No fragile heuristics.
Designed for Iteration, Not Guessing
Optimly is not just a reporting tool.
It is built to support continuous improvement.
Identify broken flows Detect hallucination patterns Find unused knowledge Reduce cost without hurting quality Prioritize product improvements
This is the difference between deploying an agent and operating one.
Stop Guessing, Start Seeing
The era of deploy and pray is over.
LLM systems are powerful, but they are opaque by default. Without proper analytics, teams cannot tell whether their agent is helping users, frustrating them, or quietly burning budget.
Optimly exists to make AI systems observable.
There is a Free forever plan, so you can start tracking your agent in minutes and scale when it makes sense.
If you are serious about building reliable AI products, visibility is not optional anymore.
Start optimizing at https://www.optimly.io